Introduction
At Gigasheet, we’re on a mission to make it easy for people to get insights from big data without specialized technical skills. It’s about making hard things easy. The same is true of ChatGPT and other Large Language Model (LLM) products that can make specialized knowledge accessible in a natural language chat. But there’s always been a limit to how much expertise can be embedded directly into a model’s training data. That’s what Anthropic aims to solve with the Model Context Protocol (MCP). That aligns well with Gigasheet’s goal of making insights more accessible, so I built an integration that connects an LLM to Gigasheet with MCP. Along the way, I found lots of rough edges with MCP, but I got a working implementation that you can try yourself in Claude Desktop. I see great potential for this kind of setup as LLM products continue to mature. Read on to learn more about the pitfalls I encountered and see how you can try it yourself.
What is the Model Context Protocol
MCP defines a general way for an LLM to request that another piece of technology does something for it. Requests over MCP come from the LLM and are fulfilled by someone’s MCP server. The MCP protocol defines an interaction flow where the LLM first asks that MCP server what actions are available, called “Tools,” and what input parameters they require. After that, the LLM may request any of those Tools be run with whatever inputs. By calling the MCP Tool, the LLM can interact with the world outside of its textual replies.
.png)
Why make a Gigasheet MCP server
Providing an MCP interface to Gigasheet seems like a perfect fit for our mission. There are already many non-technical people using LLMs to understand the world. We want to make it possible for them to use data analysis as part of that, beyond what the LLM can report from its training data. MCP offers a possible solution where Gigasheet would act as the MCP server, offering a Tool for data analysis.
The user experience we wanted was:
- The user asks a question to their LLM (e.g. to Claude), like “from this Gigasheet of healthcare data, what are the most common CPT codes?”
- The LLM, having the option to invoke the Gigasheet Tool to answer this question, sends a request to Gigasheet using MCP
- Gigasheet’s AI performs the analysis and provides an answer back over MCP to the LLM
- The LLM reports the answer to the user, all within the chat interface
In this way, anyone using an LLM with that Gigasheet Tool equipped could then count on their LLM to ask Gigasheet to help analyze very large datasets, much larger than what the LLM would be able to do on its own. This seems like a natural application of the MCP concept.
Where MCP falls short today
MCP is less than a year old, so it is not surprising that it is still on the bleeding edge. Others have come to the same conclusion. I encountered several complications that undercut our vision of empowering non-technical users, at least for now.
First, user-specified MCP Tools are only allowed on desktop LLM clients, like Claude Desktop, and are not permitted on web-based interfaces like ChatGPT.com. Since the barrier to entry is lowest for online interfaces, it is likely that more users are using LLMs in a web-based environment than the desktop tool, and they can’t use any custom MCP server today.
Second, most tutorials and examples are oriented around having a local LLM as well as a local MCP server, and the protocol itself appears to be designed for local interaction over stdin/stdout. Our vision is that the LLM uses MCP to communicate with our server, which is running on a different computer. Even if our hypothetical non-technical user has Claude Desktop, they are extremely unlikely to install some kind of custom server on their machine. I believe this will change soon, as Claude Code supports MCP over streamable HTTP as of June 18. But at least for now I did not have the option of remote MCP in regular Claude Desktop. While some folks have published proxies that route interactions over HTTP, even these proxies typically require Node or other environments to run, and I did not want to add a dependency.
Lastly, even assuming there is an MCP server running, configuring the LLM to connect to it is not yet very user-friendly. The easiest way ended up being editing a Claude configuration JSON file in my code editor. With that, we officially exit the realm of non-technical. So our vision of using MCP to democratize access to data analysis will have to wait for a little more maturity of the LLM products themselves. But we can still prototype it in expectation of future maturation of MCP!
The implementation
The core of our implementation is a new MCP endpoint on the Gigasheet API that fulfills the server side of the MCP specification. Here is an example call to this endpoint using curl:

The request asks our MCP server to describe what tools it has by specifying “method”:“tools/list”. This is one of the requests Claude Desktop will send to each MCP server it has configured when Claude Desktop launches. Our API replies with this:

The Gigasheet API reply is a JSON that describes a single Tool, called “Analyze”. It specifies that you should call Analyze with a “sheet_url” and a “query” and that you will get a response with “result”. This API endpoint is live and you can try that curl command yourself!
However, this by itself is not sufficient to allow Claude Desktop to talk to data in Gigasheet, because Claude Desktop can only interact with local tools. To solve this, I need to send Claude’s local interactions to this new endpoint. To keep ourselves closer to the vision of a non-technical user, I wanted to enable this without having to install any additional dependencies. So, my tool of choice is Python with the standard library only, which is available on most consumer systems today. Claude expects to run a command that will run a process forever, piping input to it on stdin and receiving responses on stdout. I implemented that with this Python one-liner:

That runs an infinite loop that consumes lines of stdin, issues an HTTP request with the line as the body, and then writes the HTTP response to stdout. In case other people wish to use it, the URL of the HTTP endpoint along with authorization header and value are environment variables, so feel free to use this as a simple request/response HTTP proxy for other MCP tools too.
To tell Claude Desktop about our MCP server, I had to edit a config file called claude_desktop_config.json. Here’s my complete version of that file, with the Python one-liner from above and the environment variables to point it to Gigasheet:
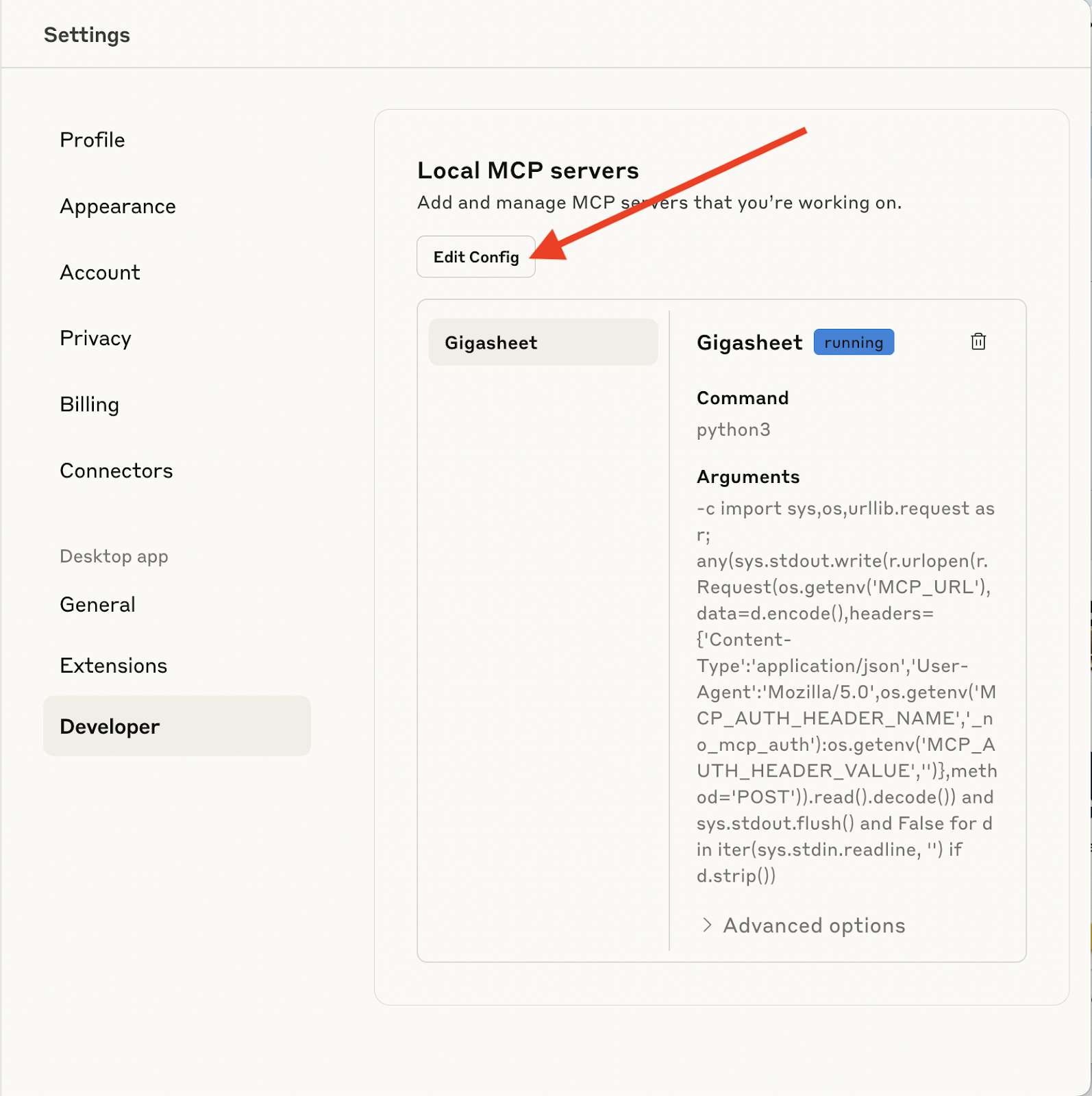
To try it yourself in Claude Desktop, open Settings, go to Developer, then choose Edit Config and paste in the text above. You’ll also need a Gigasheet API key to replace the x’s in MCP_AUTH_HEADER_VALUE.
The future of MCP and Gigasheet
The future of MCP is exciting. I am confident that Anthropic, OpenAI, and other teams developing LLM products will smooth out these rough edges. For now, it was fun to work through these challenges myself and experience this new piece of LLM technology. My optimistic vision for MCP is that it can evolve beyond something that is useful for developers into something that makes technology more accessible to everyone. As LLM products mature, MCP can be a way for LLMs to get the best of everything that’s out there, without having to bake everything into training data. At Gigasheet, we aim to be part of that future by being the easiest big data analysis tool, whether that’s in an LLM or not.
Gigasheet helps you turn big data into competitive insights and uncover growth opportunities. Contact sales@gigasheet.com to learn more about our MCP endpoint or any other part of our solution.
The intelligence layer for price transparency.

Similar posts
%20(2).png)